Die 32-bit-float-Technologie erweitert den Dynamikbereich bei der Audioaufzeichnung
Besser auflösen
von Timo Landsiedel,
Lange Zeit tat sich im Format der Audio-Aufzeichnung wenig.WAV war der Standardcodec, 24 bit galt als exzellente Auflösung. Doch seit kurzem kommt Bewegung in die digitalen Audioformate. 32-bit-float heißt die Technologie, die den Gain-Regler in den Ruhestand schicken soll. Aber ist das wirklich so? Was muss man beachten und wofür eignet sich das Format nicht?
Kameraleute kennen die Eigenschaften guter Audiosignale vor allem aus den technischen Spezifikationen ihrer Broadcast-Kameras. Da tat sich lange Zeit nicht viel. „PCM“ und „24 bit“? Passt! Doch seit kurzem kommen Audiorekorder auf den Markt, die mit 32-bit-float-Technologie ausgestattet sind. Ihr Versprechen: Nie wieder Ton pegeln. Ist das wirklich so? Um 32-bit-float zu verstehen, muss erst einmal durchdrungen werden, was mathematisch in der Aufzeichnung von Audiodateien steckt. Deren wichtigste Eigenschaften sind die Samplingrate und die Samplingtiefe. Bei einer digitalen Aufnahme eines analogen Signals wird dieses in zigtausende digitale Momentaufnahmen aufgelöst. Die Samplingrate ist die Häufigkeit dieser Snapshots – oder korrekter Samples, zum Beispiel 44.100 Hz, die typische Abtast- oder Samplerate einer CD. Je höher dieser Wert, desto naturgetreuer das digitale Signal. Für das menschliche Gehör sind Qualitätsunterschiede jenseits einer Samplerate von 20.000 Hz nicht mehr wahrnehmbar.
Der zweite wichtige Wert ist die Samplingtiefe. Typische Bit- oder Samplingtiefen sind 8, 12, 16, 24 oder eben 32 bit. Dieser Wert steht für den Dynamikumfang eines Audiosignals. Je höher der Wert, desto mehr Dynamik hat das digitale Signal. Doch was heißt das konkret? Im Tonbereich finden wir überwiegend Samplingtiefen von 16 und 24 bit und das hat einen Grund. Denn diese Werte decken einen Dynamikbereich von 96 dB bei 16 bit und 144 dB bei 24 bit ab. Wenn wir uns die Dynamik der menschlichen Stimme in einer Filmszene vorstellen, kann diese vom Flüstern bei 20 oder 30 dB bis zum Schreien bei etwa 120 dB variieren. Also decken 16 und 24 bit sehr viel von dem ab, was man sich an Geräuschen an einem Filmset vorstellen kann. Da muss schon ein Flugzeug mit 130 dB abheben, um in die Nähe der bei 24 bit möglichen 144 dB zu kommen.
Bei den mit 24 bit aufgezeichneten Audiosignalen am Filmset muss man allerdings den Gain-Regler dem aufgezeichneten Tonsignal anpassen. Wird etwa Flüstern aufgenommen, wird höher gedreht, schreit sich der Cast an, muss heruntergepegelt werden. Das kann dazu führen, dass bei hoher Empfindlichkeit zu laute Signale clippen und bei niedriger Empfindlichkeit zu leise Signale bei der dann nötigen Verstärkung in der Postproduktion auch das Grundrauschen mit anheben.
Für ein qualitativ besseres Audiosignal ist also eine höhere Samplingtiefe wichtig. Bei 32 bit sind nun theoretisch rund 1.528 dB Dynamik möglich. Das ist absurd hoch, wenn man bedenkt, dass schon die Explosion einer Atombombe „nur“ etwa 280 dB erreicht.
Aber eine höhere Bittiefe hat trotzdem praktische Vorteile. Zum einen kann das analoge Audiosignal lauter, also mit mehr Schalldruck, aufgezeichnet werden, ohne digitales Clipping zu verursachen. Zum anderen wird das Signal mit einem höheren Abstand zum Grundrauschen aufgezeichnet. Beim Clipping werden Informationen jenseits eines be- stimmten Werts nicht aufgezeichnet, sie gehen für immer verloren, werden also im Umwandlungsvorgang analog zu digital nicht „hinübergerettet“. Bei höherer Dynamik können auch Signale aufgezeichnet werden, die bei geringerer Bittiefe längst geclippt hätten. Der bessere Rauschabstand führt dazu, dass auch leisere Aufnahmen in der Digital Audio Workstation oder im nichtlinearen Schnitt angehoben werden können, ohne dass das Grundrauschen signifikant verstärkt wird. Beide Eigenschaften führen zur saloppen Formulierung, man könne in Zukunft den Gain-Regler vergessen.
Tentacle Track E und Zoom F6 sind Beispiele für Audiorekorder mit 32-bit-float-Technologie. (Fotos: Tentacle Sync / Zoom)
So funktioniert es
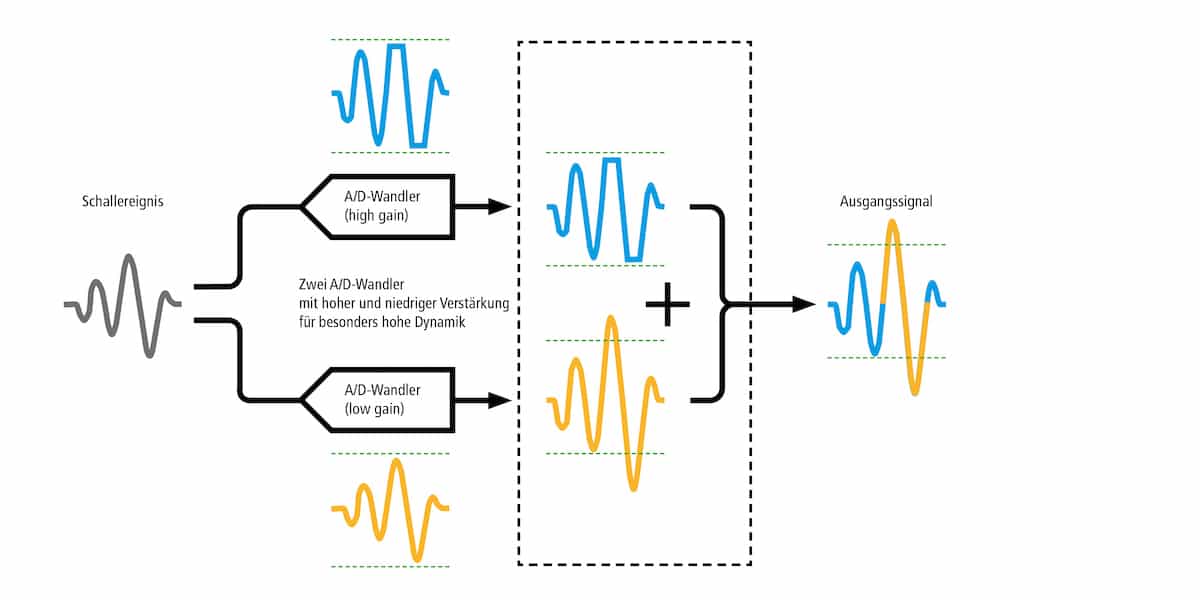
Wie kann denn der enorme Wert von 1.528 dB erreicht werden? Wie schon erahnbar, ist dieser ein theoretischer, also mathematischer Wert. Das Herz von 24-bit-Rekordern ist ein singulärer Analog-Digital-Wandler (ADC). Dieser muss den gesamten Dynamikbereich erfassen und in Echtzeit in ein digitales Signal umwandeln. Der Eingangspegel wird so angepasst, dass das analoge Digital innerhalb dieses Dynamikfelds bleibt.
Bei der 32-bit-float-Aufzeichnung wird die Arbeit von zwei A/D-Wandlern erledigt. Der eine ist mit hoher Verstärkung für leise Signale, der zweite mit niedriger Verstärkung für laute Signale zuständig. Beide Signale werden schließlich zusammengerechnet und ergeben so den hohen Dynamikumfang. Da mehr Informationen aufgezeichnet werden, ist logisch, dass sich auch der Speicherplatz der 32-bit-Float-Daten erhöht. Er liegt etwa ein Drittel über dem von 24-bit-Aufnahmen. Aber Achtung: Beim Abhören sind eventuelle Verzerrungen noch vorhanden. Erst beim Bearbeiten in der Post entfaltet sich das volle Potenzial der 32-bit-float-Aufzeichnung.
Fazit
Löst 32-bit-float alle Audioprobleme am Set? Gibt es irgendwann nur noch einen roten Knopf und der Tonmeister macht Feierabend? Natürlich nicht! Denn Audioprobleme am Motiv, wie eine laute Klimaanlage oder die Autobahn neben dem idyllischen See sind nach wie vor unerwünschter Lärm, die auch eine 32-bit-float-Aufzeichnung nicht vermeiden wird. Hier kommt es nach wie vor auf qualitativ hochwertige Mikrofone, die Wahl der geeigneten Mikrofontechnologie und der korrekten Mikrofonierung an. Zudem muss bedacht werden, dass das Einrichten des Pegels und die Aufbereitung des Audiomaterials in der Postproduktion stattfinden. Es wird also lediglich Aufwand vom Set weg verlagert.
In einem störungsfreien Umfeld jedoch wird 32-bit-Float einen echten Unterschied machen und in anderen Umgebungen immerhin die Gain-Problematik in den Hintergrund treten lassen. Für dokumentarische Formate kann die neue Technologie ein echter Gamechanger sein, weil es die Beschäftigung mit dem Ton am Set auf ein Minimum reduziert und so vor allem für kleine Teams mehr Freiheit schafft. [15393]
 Kameraleute kennen die Eigenschaften guter Audiosignale vor allem aus den technischen Spezifikationen ihrer Broadcast-Kameras. Da tat sich lange Zeit nicht viel. „PCM“ und „24 bit“? Passt! Doch seit kurzem kommen Audiorekorder auf den Markt, die mit 32-bit-float-Technologie ausgestattet sind. Ihr Versprechen: Nie wieder Ton pegeln. Ist das wirklich so? Um 32-bit-float zu verstehen, muss erst einmal durchdrungen werden, was mathematisch in der Aufzeichnung von Audiodateien steckt. Deren wichtigste Eigenschaften sind die Samplingrate und die Samplingtiefe. Bei einer digitalen Aufnahme eines analogen Signals wird dieses in zigtausende digitale Momentaufnahmen aufgelöst. Die Samplingrate ist die Häufigkeit dieser Snapshots – oder korrekter Samples, zum Beispiel 44.100 Hz, die typische Abtast- oder Samplerate einer CD. Je höher dieser Wert, desto naturgetreuer das digitale Signal. Für das menschliche Gehör sind Qualitätsunterschiede jenseits einer Samplerate von 20.000 Hz nicht mehr wahrnehmbar.
Kameraleute kennen die Eigenschaften guter Audiosignale vor allem aus den technischen Spezifikationen ihrer Broadcast-Kameras. Da tat sich lange Zeit nicht viel. „PCM“ und „24 bit“? Passt! Doch seit kurzem kommen Audiorekorder auf den Markt, die mit 32-bit-float-Technologie ausgestattet sind. Ihr Versprechen: Nie wieder Ton pegeln. Ist das wirklich so? Um 32-bit-float zu verstehen, muss erst einmal durchdrungen werden, was mathematisch in der Aufzeichnung von Audiodateien steckt. Deren wichtigste Eigenschaften sind die Samplingrate und die Samplingtiefe. Bei einer digitalen Aufnahme eines analogen Signals wird dieses in zigtausende digitale Momentaufnahmen aufgelöst. Die Samplingrate ist die Häufigkeit dieser Snapshots – oder korrekter Samples, zum Beispiel 44.100 Hz, die typische Abtast- oder Samplerate einer CD. Je höher dieser Wert, desto naturgetreuer das digitale Signal. Für das menschliche Gehör sind Qualitätsunterschiede jenseits einer Samplerate von 20.000 Hz nicht mehr wahrnehmbar.






